 Obrázek 1: Minipočítač PDP 11 (1970)
Obrázek 1: Minipočítač PDP 11 (1970)(na snímku Dennis Ritchie a Kenneth Thompson, tvůrci UNIXu)
| [Obsah] | [Cvičení 2] |
Obrázek 1: Minipočítač PDP 11 (1970)main a představuje hlavní program
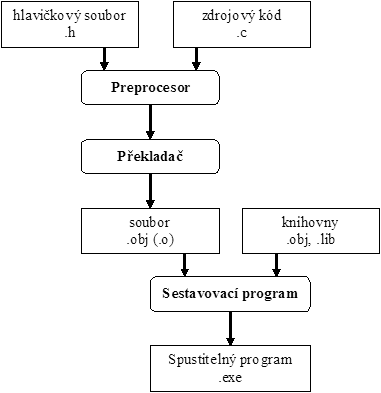
Obrázek 2: Překlad v jazyce C
#include. Pomocí této direktivy se vkládá
do zdrojového kódu soubor s hlavičkami funkcí (soubor s příponou .h); takto lze
samozřejmě vložit jakýkoliv textový soubor. Hlavičkových souborů je několik
desítek a bývají uloženy zpravidla v podadresáři include adresáře
s programovým balíkem překladače. My prozatím uvedeme několik základních
hlavičkových souborů, které budeme používat:
| Název hlavičkového souboru | Popis |
|---|---|
stdio.h |
Standard input-output (standardní vstup a výstup). Obsahuje funkce pro výstup v textovém módu na obrazovku a vstup z klávesnice (obecně na standardní výstup/ze standardního vstupu). |
conio.h |
Console input-output. Doplňkové funkce pro textový vstup/výstup (barvy, posuvy kurzoru, pro PC a DOS). |
stdlib.h |
Standard library. Obsahuje některé speciální funkce, např. možnost volání příkazů DOSu z programu, převodní funkce číselných hodnot na textové vyjádření, generátor náhodných čísel aj. |
math.h |
Matematické funkce a konstanty. |
Programovací jazyk C byl navržen ve svém základě jako velmi úsporný, aby jádro
jazyka bylo co nejméně závislé na cílové platformě. Proto nejsou součástí jazyka
ani příkazy pro vstup a výstup na obrazovku, ale existují ve formě funkcí
v externích knihovnách. Základní funkce jsou uvedeny v souboru
stdio.h, bez něhož bychom nenapsali žádný program v jazyce C,
který by vypisoval cokoliv na obrazovku.
Hlavičkový soubor vložíme uvedením direktivy na počátku zdrojového kódu:
#include <stdio.h>
Pokud jméno hlavičkového souboru vložíme mezi znaky < a >, hledá
preprocesor hlavičkový soubor ve standardní adresáři překladače s hlavičkovými
soubory (zpravidla také adresář s názvem include). Je-li jméno souboru mezi
uvozovkami, např. #include "seznam.h", hledá překladač soubor
v aktuálním adresáři projektu. Lze uvést i cestu, syntaxe se řídí daným
operačním systémem.
Další velmi využívaná direktiva je #define. Umožňuje definovat tzv. symbolickou konstantu (jazyk C neměl
ve verzi K&R klíčové slovo const, to bylo doplněno až do ANSI C), např. #define MAX 10.
Preprocesor nahradí ve zdrojovém kódu všechny výskyty řetězce MAX řetězcem 10. Náhradu ilustruje následující příklad,
včetně direktivy #include.
Předpokládejme, že soubor definice.txt obsahuje jeden řádek:Opět připomínám, že původní zdrojový kód zapsaný programátorem se nemění, zpracování preprocesorem je pouze „vnitřní“, programátor výsledek normálně nevidí. Je však možné u většiny překladačů nechat provést pouze zapracování preprocesorem a výsledek zobrazit, resp. uložit (viz dále).
float obsah(float a, float b);Zdrojový kód má podobu:
#include "definice.txt" #define MAX 10 int main(int argc, char **argv) { ... if (x > MAX) printf("Limit je %d",MAX); ... }Tedy, po zpracování preprocesorem bude mít zdrojový kód podobu:float obsah(float a, float b); int main(int argc, char **argv) { ... if (x > 10) printf("Limit je %d",10); ... }
Direktiva #define slouží také k definici makra. Ukážeme definici makra SOUCET s parametry, které počítá součet dvou čísel:
#define SOUCET(a,b) (a+b)
int main(int argc, char **argv)
{
int x;
...
x = 3*SOUCET(2,3);
...
}
Preprocesor přímo nahradí ve zdrojovém kódu výskyt SOUCET(2,3) řetězcem (2+3):
int main(int argc, char **argv)
{
int x;
...
x = 3*(2+3);
...
}
Závorky v definici makra (a+b) jsou důležité.
Pokud bychom je v definici makra nenapsali, tedy zápis by vypadal #define SOUCET(a,b) a+b, preprocesor by provedl náhradu
přesně podle definice, tj. x = 3*2+3;. Vzhledem k prioritě operátorů je výsledný výraz jiný, než programátor zřejmě původně zamýšlel.
Při definici makra je tedy potřebné uvědomit si všechny souvislosti. Správná definice makra SOUCET obsahuje ještě další závorky: #define SOUCET(a,b) ((a)+(b))
Pomocí zmíněné direktivy je možné definovat pouze symbol (identifikátor), např. #define PRACOVNI. Využijeme jej v podmíněném překladu,
kdy pomocí direktiv #ifdef, resp. #ifndef řídíme, které části kódu má preprocesor vypustit a které ponechat.
Ukážeme si program s podmíněným překladem, kdy využijeme tento princip při ladění. Definujeme symbol LADENI a do kódu napíšeme
podmínku v podobě direktivy preprocesoru #ifdef. Do ní vložíme kontrolní výpis, který bude ve výsledném programu
po odladění vynechán.
#include <stdio.h>
#define LADENI
int main(int argc, char **argv)
{
int x;
printf("Zadej cele cislo");
scanf("%d",&x);
#ifdef LADENI
printf("Zadal jsi %d\n",x);
#endif
...
return 0;
}
Poznámka: volání funkce printf nesmí být na stejném řádku jako direktiva.
Protože je symbol LADENI předem definován, preprocesor ponechá v textu volání funkce printf. Po ukončení ladění programu direktivu
#define LADENI zakomentujeme a provedeme ještě jednou překlad. Pracovní výpis pak v programu nebude.
Další využití podmíněného překladu spočívá v možnosti řídit překlad podle různých požadavků. Předpokládejme, že máme nějaké dvě knihovny (dva hlavičkové soubory), jedna obsahuje definice datových typů s optimalizací pro 32 bitový procesor (vypocty32.h) a druhá datové typy s optimalizací pro 64 bitový procesor (vypocty64.h). Chceme napsat univerzální program, který bychom mohli bez složitých úprav jednoduše přeložit buď ve 32 nebo 64 verzi. Pomocí direktiv to provedeme snadno:
#define PREKL32
#ifdef PREKL32
#include "vypocty32.h"
#else
#ifdef PREKL64
#include "vypocty64.h"
#else
#error Musi byt definovan symbol PREKL32 nebo PREKL64
#endif
#endif
...
Pokud zapomeneme symbol definovat, preprocesor vykoná direktivu #error - vypíše chybové hlášení
a zastaví překlad.
/* */.
Komentáře mohou být víceřádkové a nesmějí být vnořeny (tzv. nested comments)!
Komentáře jsou odstraněny preprocesorem.
Většina současných překladačů, které jsou zároveň překladači jazyka C++,
dovolují používat jednořádkové komentáře ve stylu C++, tj. uvozené //.
Tyto komentáře platí do konce řádku a nemají ukončující element.
Celočíselné desítkové konstanty se zapisují běžným způsobem, např. 10, -5.
Je možné zapsat celočíselné konstanty také v osmičkové nebo šestnáctkové soustavě.
Zápis v osmičkové soustavě začíná nulou, tj. 012, 03.
Zápis v šestnáctkové soustavě začíná 0x nebo 0X,
např. 0x20, 0xFE, 0X3f, 0x2a.
Desetinná čísla zapisujeme také obvyklým způsobem, pro oddělení celé a desetinné
části používáme desetinnou tečku, např. 3.14, -6.354, 0.5.
U čísel menších než 1 lze úvodní nulu vynechat, tedy .4 je totéž jako 0.4.
Číslo lze zapsat i v tzv. semilogaritmickém tvaru -
4.25E-3, -1e6. Zápis znamená 4,25.10-3 a
-1.106.
Znakové konstanty se uzavírají mezi apostrofy, např., 'a', 'A', 'x', '4',
'*'. Potřebujeme-li zapsat konstantu neviditelného (řídicího) znaku,
použijeme zápis ve tvaru '\ddd', kde ddd je osmičkový zápis
kódu (kódu ASCII) příslušného znaku, resp. '\0xHH', kde HH
je šestnáctkový zápis, např. '\0x0A' je znak nová řádka (LF).
Pro nejpoužívanější řídicí znaky existují znakové ekvivalenty, uvedené v tab. 1:
| Ekvivalent | Význam |
'\n' | nová řádka (LF) |
'\r' | návrat na začátek řádky (CR) |
'\f' | nová stránka (FF) |
'\t' | tabulátor (TAB) |
'\b' | posun doleva (back space) |
'\a' | pípnutí (BELL) |
'\\' | lomítko |
'\'' | apostrof |
'\0' | nulový znak, NULL, znak s ASCII kódem 0 |
Tabulka 1: Znakové ekvivalenty
Znakové konstanty nemají velikost 1 Byte, ale int.
Ačkoliv jazyk C nemá typ řetězec, lze zapsat řetězcové konstanty. Řetězcové konstanty se uzavírají do uvozovek, např. "Ahoj, světe!".
Proměnné (variables) v programovacím jazyce uchovávají určitou hodnotu (data), jejich obsah se může během výpočtu měnit. Proměnná vlastně představuje abstrakci adresy paměťové buňky, ve které jsou data uložena.
Jazyk C patří mezi tzv. jazyky s deklarovanými a typovanými proměnnými. Znamená to, že před použitím jakékoliv proměnné v kódu programu je nutné proměnnou deklarovat (neformálně, napsat seznam proměnných). Termín typované proměnné značí, že u každé proměnné je povinnost uvést, jakého je datového typu. Datový typ determinuje hodnoty, které může proměnná obsahovat (neboli typ určuje množinu hodnot) a také množinu operací, které je možné s proměnnými provádět.
Povinnost deklarovat proměnné má výhodu pro programátory v tom, že překladač snadno odhalí překlepy programátora v názvech (identifikátorech) proměnných. Určení typu proměnné umožňuje kontrolovat při překladu, zda programátor nepřiřazuje proměnné nesmyslná data nebo nepíše do kódu nepovolené či „podivné“ operace, např. se nepokouší sčítat znaky (jazyk C na rozdíl od Pascalu ale tuto operaci dovolí, protože se jedná o jazyk se slabou typovou kontrolou, kdy se kontrola provádí pouze na úrovni vnitřní reprezentace). Typování proměnných překladači umožní také generovat efektivní kód.
| Skupina | Typ | Charakteristika |
|---|---|---|
| Znakový typ | char | Obsahuje znaky, velikost 1 Byte |
| Celočíselné typy | short | |
int | Základní celočíselný typ | |
long | ||
| Typy v pohyblivé řádové čárce | float | Desetinná čísla s jednoduchou přesností |
double | Desetinná čísla s dvojitou přesností | |
long double | Nový typ v normě ANSI C |
Tabulka 2: Jednoduché datové typy v jazyce C
Norma jazyka nedefinuje velikost celočíselných typů, pouze musí platit sizeof(short)<=sizeof(int)<=sizeof(long).
Výsledkem operátoru sizeof() je počet bytů, na kolik je typ v daném překladači implementován.
Větší počet bytů znamená přirozeně větší rozsah zobrazitelných čísel. Základní celočíselný
typ je typ int, měl by být implementován „nejvýhodněji“ pro danou platformu (např. pro 32 bitový překladač
by měl mít velikost 32 bitů).
Celočíselné typy jsou standardně v reprezentaci se znaménkem (bit nejvyššího řádu je znaménkový, čísla jsou uložena v tzv. doplňkovém kódu),
např. 16 bitový celočíselný typ má rozsah zobrazitelných čísel -32768 až +32767. Pro reprezentaci čísel bez znaménka existuje v jazyce klíčové
slovo unsigned, kterým typ modifikujeme - unsigned short, unsigned int, unsigned long, typ unsigned int
je možné zkrátit na unsigned. Klíčové slovo signed ve verzi K&R neexistovalo, bylo doplněno až ve verzi ANSI.
Typ char má velikost 1 slabiku (1 Byte) a na proměnné tohoto typu je možné v jazyce C nahlížet také jako na čísla (jazyk C je jazyk
se slabou typovou kontrolou!). Reprezentace typu char je zpravidla se znaménkem, závisí na překladači.
Do proměnných typu float a double je možné uložit desetinná čísla, typ double má dvojitou přesnost,
tj. větší počet desetinných míst. Čísla v této reprezentaci jsou interně uložena jako trojice znaménko, mantisa, exponent. Tato reprezentace je čtenáři
dobře známa ze zápisů čísel zejména ve fyzice, např. -3,4x102, kde znaménko je zřejmé, 3,4 je mantisa, 2 je exponent.
Mantisa i exponent jsou uloženy pochopitelně ve dvojkové soustavě.
Poznámka: Celočíselné konstanty jsou standardně typuNa rozdíl od jiných jazyků neexistuje typ boolean, který by nesl logické hodnoty pravda/nepravda. Místo toho se používá celočíselný typint, chceme-li explicitně vyjádřit konstantu typulong, připojíme za zápis čísla příponuL, např.126L, obdobněUpro typunsigned. Desetinné konstanty jsou typudouble, konstantu typufloatzapíšeme pomocí příponyF,1.6F.
int,
kdy jakákoliv nenulová hodnota je chápána jako pravda (true) a nulová hodnota jako nepravda (false). Neexistuje typ řetězec (string), představující text, je
nahrazen polem znaků (ale řetězcovou konstantu zapsat lze).
Poznámka: V jazyce C++ již existuje datový typbool, jehož oborem hodnot jsou dvě hodnotytrue/false(pravda/nepravda).
Deklarace proměnné v jazyce C se zapíše tak, že nejprve uvedeme typ proměněné a pak indentifikátor proměnné identifikátor je název proměnné). Identifikátor nesmí začínat číslicí a nesmí dále obsahovat znaky sloužící jako operátory (+.-,! atd.), závorky aj. Deklarace se ukončí středníkem. V rámci jednoho zápisu lze deklarovat více proměnných stejného typu, oddělených čárkou.
Příklad: Nadeklarujeme jednu proměnnou c typu char, dvě proměnné a, b typu int
a proměnnou polomer typu float.
char c; int a, b; float polomer;
Jazyk C dovoluje provést počáteční přiřazení hodnoty proměnné již při deklaraci, např.:
int a=3, b;
Proměnná a má tedy hodnotu 3, proměnná b je neinicializovaná, obsahuje náhodnou hodnotu.
Proměnné mohou být globální a lokální. Globální proměnné jsou deklarovány vně jakékoliv funkce a jsou viditelné (použitelné)
v celém zdrojovém kódu, lokální proměnné jsou lokální pouze v daném bloku, tj. části kódu uzavřené mezi { }.
int volba; /* Toto je globální proměnná, viditelná ve funkci obsah i v hlavním programu */
int obsah()
{
float x, y; /* Proměnné x a y jsou lokální ve funkci obsah */
}
int main(int argc, char **argv)
{
int a; /* Lokální proměnná viditelná pouze v hlavním programu */
}
Podle pravidel jazyka C je nutné v bloku uvést nejprve všechny deklarace proměnných a pak programový kód. Podle normy C++ je možné psát deklarace nových proměnných i uprostřed programového kódu.
Příklad:
int a, b; float x, y; a = 3; b = 3*a; /* násobení */ x = y = 3.5; /* vícenásobné přiřazení */Zápis přiřazení typu
x = x + 3 můžeme nahradit přiřazovacím operátorem x += 3. Obecně, zápis
E1 = E1 op E2 lze nahradit zápisem E1 op= E2, E2 může být libovolný výraz. Operátor je libovolný
binární (aritmetický, logický, operátor posuvu).
Vyvíjet a ladit programy můžeme v několika prostředích. Na fakultě je k dispozici
komerční překladač CodeGear C++ Builder 2009 od firmy Borland, dále volně stažitelná
verze překladače firmy Microsoft MS Visual Studio C++ (s omezenými funkcemi), volně
šířitelné prostředí Dev C++ (je založeno na volně šířitelném překladači gcc),
který si můžete stáhnout z internetu,
www.bloodshed.net/devcpp.html
(instalace je též na fakultním disku H:\studenti\PRG1\DevC\).
Volně šířitelné prostředí Dev C++ má méně komfortní možnosti krokování programů.
Příjemné uživatelské rozhraní má také volně šířitelný překladač CodeBlocks, jehož
základem je také překladač gcc,
www.codeblocks.org
(instalace je na fakultním disku H:\studenti\PRG1\CodeBlocks\).
Napište program, který vypočítá obsah a obvod obdelníka. Vyzve uživatele k zadání dvou stan obdelníka a vypíše výsledky. Vyzkoušejte si práci s několika překladači instalovanými v učebně, zaměřte se na ladění programu - krokování, výpis proměnných (watches) a nastavování breakpointů.
Řešení:
Dev C++: obsah.dev, obsah.c CodeBlocks: obsah.cbp, obsah.c
| [Obsah] | [Cvičení 2] |