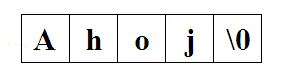
Obrázek 1: Uložení řetězce v paměti
| [Přednáška 4] | [Obsah] | [Přednáška 6] |
string.h
sprintf a sscanfstring v jiných jazycích) neexistuje
(až v C++ v knihovně STL je typ string implementován).
Existují řetězcové konstanty, které jsou uzavřeny v uvozovkách, např. "Ahoj". Řetězcové
konstanty jsme využívali jako formátovací řetězec ve funkcích printf a scanf,
např. printf("Soucet: %d",a+b);, řetězcová konstanta je zde "Soucet: %d".null), který se zapisuje ve zdrojovém kódu
pomocí lomítka jako prefixu: '\0'. Z toho vyplývá, že paměť potřebná pro uložení řetězu má velikost o 1 slabiku větší,
než je délka řetězce.
Tedy, řetězec Ahoj má délku 4 znaky, ale pro jeho uložení je potřeba paměť o velikosti 5 bytů, viz obrázek 1.
Obrázek 1: Uložení řetězce v paměti
char ret1[10]; char *ret2; char *ret3; ret1 = "Ahoj"; // zde překladač ohlásí chybu ret2 = "Ahoj"; // zde nekopírujeme vlastní řetězec, ale pouze ukazatel na konstatní řetězecPrvní přiřazovací příkaz je chybný a překladač zde ohlásí chybu typu „konstantní ukazatel nelze přepsat“. U druhého přiřazovacího příkazu překladač chybu neohlásí, ale přiřazení v tomto případě také není zcela správné. Nejde totiž o přiřazení vlastního řetězce či kopii řetězce, ale do ukazatele
ret2 se přiřadí adresa paměti, kde je překladačem umístěna řetězcová
konstanta "Ahoj". Řetězcové funkce budou s tímto řetězcem správně pracovat, bude-li se z řetězce pouze číst,
potíže mohou nastat, budeme-li do řetězce zapisovat.
Vrátíme se k poli ret1. Správné nastavení hodnoty řetězce pole ret1 je možné provést dvěma způsoby:
char ret1[10] = "Ahoj";strcpy z knihovny
string.h (odstavec o zmíněné knihovně viz Knihovna string.h):char ret1[10]; ... ... strcpy(ret1,"Ahoj");
ret1 délky 10 znaků, můžeme kopírovat do tohoto pole řetězce o maximální délce 9 znaků
(poslední položka pole je využita pro ukončující znak '\0').
Pro řetězec ret2 je potřeba nejprve dynamicky alokovat paměť (pole). Do tohoto pole budeme opět kopírovat řetězec
"Ahoj", délku alokovaného určíme přesně podle délky pozdravu "Ahoj". K tomu využijeme funkci
strlen, která vrací délku řetězce bez ukončujícího znaku! Při alokaci musíme tedy zvětšit požadavek na velikost
paměti o 1:
ret2 = (char*)malloc(strlen("Ahoj")+1);
strcpy(ret2,"Ahoj");
Pokud napíšeme do kódu následně přiřazení ret3 = ret2;, přiřadili jsme ukazatel na začátek dynamického pole také do proměnné
ret3. Oba ukazatelé ukazují na stejný řetězec (opět nejde tedy o kopii řetězce, pouze o kopii ukazatelů); při změně
řetězce ret2 se mění i řetězec ret3 (často budeme ale přiřazení ukazatelů využívat, např. uložení
ukazatele na počátek řetězce do pomocné proměnné, kterou pak budeme po poli posouvat).
printf, kde ve formátovacím řetězci uvádíme specifikátor
%s. Následující fragment kódu vytiskne na dva řádky pozdrav:
char pozdrav[10] = "Ahoj";
printf("%s\n%s",pozdrav,pozdrav);
Vstup řetězců z klávesnice je možné provádět pomocí funkce scanf, např. scanf("%s",pozdrav).
Chování funkce má jeden „háček“. Víme, že funkce scanf konvertuje znaky ze vstupního bufferu, dokud nenarazí na
tzv. bílé znaky (white characters), což jsou: mezera, tabulátor či konec řádku (ev. souboru). Zadáme-li z klávesnice text
„Ahoj, Pepiku“, načte se do pole pozdrav pouze text „Ahoj,“,
protože za ním následuje mezera.
V takovém případě je lépe použít funkci char *gets(char *s) z knihovny stdio.h, která načte
celý zadaný řádek včetně mezer (až do stisku klávesy Enter). Znak konce řádku není do řetězce vložen, na konec je automaticky
přidán ukončující znak '\0'. Funkce gets neprovádí kontrolu přetečení, zda načtený řetězec není
delší nez alokované pole. Načtení celého řádku z klávesnice do pole ukazuje následující fragment kódu:
char radek[80]; gets(radek);Nevýhoda spočívající v možnosti přetečení se odstraní použitím funkce
fgets, která se používá pro čtení celého
řádku ze souboru. Tato funkce má za parametr maximální délku pole a hlídá přetečení. Jako identifikace souboru se používá
označení standardního vstupu stdin. Tedy, řetězec z klávesnice do pole o alokované délce 80 znaků načteme
pomocí funkce fgets následovně:
char radek[80]; fgets(radek,80,stdin);Funkce přečte z klávesnice řádek textu. Čte tak dlouho, dokud nenarazí na znak konce řádku nebo nepřečetla 79 (obecně n-1) znaků. Na rozdíl od gets funkce ponechá znak konce řádku v řetězci a za něj umístí ukončující znak NULL. Více v kapitole o souborech.
string.h. Identifikátory funkcí začínají vždy předponou str,
další část identifikátoru je zkratkou operace, např. strcpy pro kopii řetězců (jako copy),
strcmp pro porovnání řetězců (jako compare).
V tabulce uvedeme přehled nejpoužívanějších funkcí, pro získání detailních informací odkazujeme čtenáře na manuály překladače a hlavičkový souborstring.h. Upozorníme jen, že většina funkcí předpokládá, že všechny alokace paměti jsou provedeny před voláním funkce, tj. např. před voláním funkcestrcpymusí být paměť pro cílový řetězec již alokována, funkce sama žádnou alokaci neprovádí.
Funkce pracující s řetězci Hlavička funkce Význam int strlen(const char *s)Vrátí délku řetězce bez ukončujícího znaku '\0'.char *strcpy(char *s1, const char *s2)Zkopíruje obsah řetězce s2 do s1. Vrátí ukazatel na počátek řetězce s1 (paměť pro s1 musí být již alokována, přetečení se nekontroluje). char *strcat(char *s1, const char *s2)Připojí obsah řetězce s2 za konec řetězce s1. Vrátí ukazatel na počátek řetězce s1 (paměť pro s1 musí být alokována po velikost řetězce po spojení, přetečení se nekontroluje). char *strchr(const char *s, char c)Nalezení znaku c v řetězci. Pokud se znak c vyskytuje v řetězci s, pak funkce vrátí ukazatel na jeho první výskyt. V případě neúspěchu (znak v řetězci není) je vráceno NULL. int strcmp(const char *s1, const char *s2)Porovnání dvou řetězců. Funkce vrátí 0, jsou-li oba řetězce stejné. Vrátí záporné číslo, je-li s1 lexikograficky menší než s2 a kladné číslo v opačném případě. char *strstr(const char *s1, const char *s2)Nalezení podřetězce v řetězci. Nalezne první výskyt řetězce s2 v podřetězci s1 a vrátí pointer na tento výskyt nebo vrátí NULL v případě neúspěchu. char *strset(char *s, int c)Nastaví všechny znaky řetězce s na hodnotu c. Pracuje, dokud nenarazí v řetězci na znak '\0'. char *strlwr(char *s)Převede řetězec na malá písmena (bez českých znaků). Vrací ukazatel na konvertovaný řetězec. char *strupr(char *s)Převede řetězec na velká písmena (bez českých znaků). Vrací ukazatel na konvertovaný řetězec. char *strtok(char *s1, const char *s2)Postupně vrací ukazatele na části řetězce s1, které jsou odděleny.řetězcem s2. Tabulka 1: Funkce z knihovny string.h
Všimněte si, že v hlavičkách funkcí je formální parametr řetězec s2 deklarován jako
const char *s2. To znamená, že funkce nemění řetězec s2.Chování funkce
strtok(tok jako token) nejlépe vysvětlí příklad (převzatý z manuálu překladače firmy Borland):int main(void) { char input[16] = "abc,d,e"; char *p; /* odělovač je řetězec ",", při prvním volání vrátí ukazatel na počátek řetězce input, první výskyt "," je nahrazen '\0' */ p = strtok(input, ","); /* vytiskne se abc */ if (p) printf("%s\n", p); /* Druhé volání s parametrem NULL vrátí ukazatel na další část řetězce za prvním '\0', další výskyt "," je nahrazen '\0' */ p = strtok(NULL, ","); /* vytiskne d */ if (p) printf("%s\n", p); p = strtok(NULL, ","); /* vytiskne e */ if (p) printf("%s\n", p); return 0; }
V knihovně jsou také implementovány funkce, které nemusí pracovat s celým řetězcem, ale pouze s jeho částí, resp. s prvými n znaky. Přesněji, funkce ukončí svoji činnost, zpracují-li n znaků řetězce nebo narazí na ukončující znak'\0'(je-li řetězec kratší než n znaků). Identifikátory funkcí jsou odvozeny od výše zmíněných, mají pouze uprostřed identifikátoru navíc písmeno n a také jeden parametr navíc - počet znaků n, např.:strncpy,strncmpatd.Za všechny uvedeme funkci:
char *strncpy(char *s1, char *s2, int n),která zkopíruje nejvýše n znaků řetězce s2 do s1, např.strncpy(str,"napodobenina",5)zkopíruje do řetězcestrřetězec"napod", dálestrncpy(str,"ahoj",7)zkopíruje do řetězcestrřetězec"ahoj".
Další množina funkcí pracuje s řetězcem od konce. Ve svém identifikátoru mají funkce uprostřed písmeno r (reverse).
Zpracovávají řetězec od ukončujícího znaku '\0' směrem k počátku,
např. int strrchr(char *s, char c) vrátí ukazatel na poslední výskyt znaku c v řetězci s, pokud
tento znak řetězec obsahuje, jinak vrátí NULL.
Napište vlastní implementaci funkce pro kopii řetězceŘešení:
Funkci můžeme naprogramovat několika způsoby. První možností je kopírování jednotlivých prvků pole:
char *kopie(char *s1, const char *s2) /* kopíruje s2 do s1, vrací ukazatel na počátek s1 */ { int i; int delka = strlen(s2); for(i=0;i<delka;i++) s1[i] = s2[i]; s1[delka]='\0'; return s1; }V této funkci se v cyklu zkopírují do s2 všechny znaky řetězce mimo ukončujícího znaku '\0'. Musíme jej tedy nakopírovat samostatně. Jesliže má řetězec délku n znaků, poslední znak je na pozici n-1 (uvědomme si, že v C se pole indexují od 0), ukončující znak '\0' musí být na pozici n.Pokud změníme v cyklu for podmínku na
i<=delka, zkopíruje se v cyklu i ukončující znak a není nutné jej kopírovat po skončení cyklu:char *kopie(char *s1, const char *s2) /* kopíruje s2 do s1, vrací ukazatel na počátek s1 */ { int i; int delka = strlen(s2); for(i=0;i<=delka;i++) s1[i] = s2[i]; return s1; }Další, typické řešení, využívá ukazatele, jehož hodnotu zvyšujeme o 1 a tím posouváme po řetězci:char *kopie(char *s1, const char *s2) /* kopíruje s2 do s1, vrací ukazatel na počátek s1 */ { char *ps; // pomocný ukazatel ps = s1; // do něj uschovám počátek na řetězec s1, do kterého se kopíruje while (*s2 != '\0') // dokud nenarazím na konec *s1++ = *s2++; // kopíruji znak po znaku // ukončující znak se již nezkopíroval, nesmím zapomenout jej na konec řetězce s1 přidat *s1 = '\0'; return ps; } int main(int argc, char **argv) { char ret1[10]="Ahoj"; char ret2[10]; kopie(ret2,ret1); printf("%s\n",ret2); system("pause"); return 0; }
Dev C++: kopie.dev, kopie.c CodeBlocks: kopie.cbp, kopie.c
stdlib.h existuje několik funkcí pro převod mezi číselnými hodnotami a řetězci a naopak.
Přehled několika z nich uvádí tabulka 2.
| Konverzní funkce | |
| Hlavička funkce | Význam |
int atoi(const char *s)
| Převede řetězec na číslo typu int. Číslo v řetězci je v desítkové soustavě.
|
long atol(const char *s)
| Převede řetězec na číslo typu long.
|
double atof(const char *s)
| Převede řetězec na číslo reprezentované v pohyblivé řádové čárce |
char *itoa(int value, char *s, int radix)
| Převede číslo typu int na řetězec s. Radix určuje číselnou soustavu
(2 až 36), ve které má být číslo v řetězci uloženo. Paměť pro řetězec musí být alokována (v překladači Borland C++ vrací funkce
max. 33 znaků). Funkce vrací ukazatel na řetězec s.
|
char *ultoa(unsigned long value, char *s, int radix)
| Převede číslo typu unsigned long na řetězec s.
|
long strtol(const char *s, char **endptr, int radix)
| Převede řetězec na číslo typu long. Číslo v řetězci může být zapsáno v číselné soustavě o základu
2 až 36 (parametr radix). Endptr viz poznámka. Pokud dojde při převodu
k chybě, funkce vrací 0.
|
unsigned long strtoul(const char *s, char **endptr, int radix)
| Převede řetězec na číslo typu unsigned long v soustavě dané parametrem radix.
|
double strtod(const char *s, char **endptr)
| Převede řetězec na číslo typu double.
|
Tabulka 2: Konverzní funkce
ParametrPro převody mezi řetězci a číselnými proměnnými lze s výhodou použít i funkceendptrje ukazatel na ukazatel na char. Pokud není roven hodnotě NULL, funkce do tohoto ukazatele uloží ukazatel na znak, kde byla ukončena konverze. Ukazatel se dá využít, obsahuje-li řetězec několik číselných hodnot např. oddělených mezerami a potřebujeme-li postupně tato čísla převést.long pole[7]; char s[] = "1 5 7 14 10 4 -4"; char *uk; uk = s; for(int i=0;i<7;i++) pole[i] = strtol(uk,&uk,10);
sscanf a sprintf.
Tyto dvě funkce z knihovny stdio.h jsou odvozeny od známých funkcí printf a scanf. V případě funkce sprintf
není výstup směřován na terminálový výstup, ale do řetězce, obdobně, v případě funkce sscanf se textový vstup nenačítá z klávesnice (terminálového vstupu), ale
z řetězce.
Úlohu 5.1 bychom za pomoci funkceint sprintf(char *buffer, const char *format[, argument, ...]); int sscanf(const char *buffer, const char *format[, address, ...]);
sprintf řešili jednoduše takto:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main(int argc, char **argv)
{
char text1[81];
char text2[81];
char *spojeny;
printf("Zadej prvni text: ");
gets(text1);
printf("Zadej druhy text: ");
gets(text2);
spojeny = (char *)malloc(strlen(text1)+strlen(text2)+3+1);
/* hodnotu 1 pričítám na ukončující znak a hodnotu 3 na spojení pomocí spojky "a" a dvou mezer */
sprintf(spojeny,"%s a %s",text1,text2);
printf("%s",spojeny);
free(spojeny);
return 0;
}
Konverzi např. celého čísla do proměnné x z řetězce ret za použití
funkce sscanf naprogramujeme snadno: sscanf(ret,"%d",&x); Návratový kód
funkce má stejný význam jako u scanf.
| [Přednáška 4] | [Obsah] | [Přednáška 6] |